Поиск подстроки в тексте (строке). Алгоритм грубой силы. Метод грубой силы Перебор в таймере
Метод грубой силы представляет собой прямой подход к решению
задачи, обычно основанный непосредственно на формулировке задачи и определениях используемых ею концепций.
Алгоритм, основанный на методе грубой силы, для решения общей задачи поиска называется последовательным поиском. Этот алгоритм просто по очереди сравнивает элементы заданного списка с ключом поиска до тех пор, пока не будет найден элемент с указанным значением ключа (успешный поиск) или весь список будет проверен, но требуемый элемент не найден (неудачный поиск). Зачастую применяется простой дополнительный прием: если добавить ключ поиска в конец списка, то поиск обязательно будет успешным, следовательно, можно убрать проверку завершения списка в каждой итерации алгоритма. Далее приведен псевдокод такой улучшенной версии; предполагается, что входные данные имеют вид массива.
Если исходный список отсортирован, можно воспользоваться еще одним усовершенствованием: поиск в таком списке можно прекращать, как только встретится элемент, не меньший ключа поиска. Последовательный поиск представляет превосходную иллюстрацию метода грубой силы, с его характерными сильными (простота) и слабыми (низкая эффективность) сторонами.
Совершенно очевидно, что время работы этого алгоритма может отличаться в очень широких пределах для одного и того же списка размера п. В наихудшем случае, т.е. когда в списке нет искомого элемента либо когда искомый элемент расположен в списке последним, в алгоритме будет выполнено наибольшее количество операций сравнения ключа со всеми n элементами списка: C(n) = n.
1.2. Алгоритм Рабина.
Алгоритм Рабина представляет собой модификацию линейного алгоритма, он основан на весьма простой идее:
«Представим себе, что в слове A, длина которого равна m, мы ищем образец X длины n. Вырежем "окошечко" размером n и будем двигать его по входному слову. Нас интересует, не совпадает ли слово в "окошечке" с заданным образцом. Сравнивать по буквам долго. Вместо этого фиксируем некоторую числовую функцию на словах длины n, тогда задача сведется к сравнению чисел, что, несомненно, быстрее. Если значения этой функции на слове в "окошечке" и на образце различны, то совпадения нет. Только если значения одинаковы, необходимо проверять последовательно совпадение по буквам.»
Этот алгоритм выполняет линейный проход по строке (n шагов) и линейный проход по всему тексту (m шагов), стало быть, общее время работы есть O(n+m). При этом мы не учитываем временную сложность вычисления хеш-функции, так как, суть алгоритма в том и заключается, чтобы данная функция была настолько легко вычисляемой, что ее работа не влияла на общую работу алгоритма.
Алгоритм Рабина и алгоритм последовательного поиска являются алгоритмами с наименьшими трудозатратами, поэтому они годятся для использования при решении некоторого класса задач. Однако эти алгоритмы не являются наиболее оптимальными.
1.3. Алгоритм Кнута - Морриса - Пратта (кмп).
Метод КМП использует предобработку искомой строки, а именно: на ее основе создается префикс-функция. При этом используется следующая идея: если префикс (он же суффикс) строки длинной i длиннее одного символа, то он одновременно и префикс подстроки длинной i-1. Таким образом, мы проверяем префикс предыдущей подстроки, если же тот не подходит, то префикс ее префикса, и т.д. Действуя так, находим наибольший искомый префикс. Следующий вопрос, на который стоит ответить: почему время работы процедуры линейно, ведь в ней присутствует вложенный цикл? Ну, во-первых, присвоение префикс-функции происходит четко m раз, остальное время меняется переменная k. Стало быть, общее время работы программы есть O(n+m), т. е. линейное время.
У меня есть математическая проблема, которую я решаю методом проб и ошибок (я думаю, это называется грубой силой), и программа отлично работает, когда есть несколько параметров, но по мере добавления дополнительных переменных/данных требуется больше времени и дольше для запуска.
Моя проблема заключается в том, что, хотя прототип работает, он полезен для тысяч переменных и больших наборов данных; поэтому, мне интересно, можно ли масштабировать алгоритмы грубой силы. Как я могу подойти к его масштабированию?
3 ответа
Как правило, вы можете количественно оценить, насколько хорошо алгоритм будет масштабироваться, используя нотацию большого вывода для анализа ее темпа роста. Когда вы говорите, что ваш алгоритм работает под "грубой силой", он неясно, в какой степени он будет масштабироваться. Если ваше решение "грубой силы" работает, перечисляя все возможные подмножества или комбинации набора данных, то оно почти наверняка не будет масштабироваться (оно будет иметь асимптотическую сложность O (2 n) или O (n!), соответственно). Если ваше решение для грубой силы работает, найдя все пары элементов и проверив их, оно может масштабироваться достаточно хорошо (O (n 2)). Однако, без дополнительной информации о том, как работает ваш алгоритм, это трудно сказать.
По определению алгоритмы грубой силы глупы. Вам будет намного лучше с более умным алгоритмом (если он у вас есть). Лучший алгоритм уменьшит работу, которая должна быть выполнена, надеюсь, в той степени, в которой вы можете это сделать, не требуя "масштабирования" на нескольких машинах.
Независимо от алгоритма, наступает момент, когда требуемое количество данных или вычислительная мощность настолько велики, что вам нужно использовать что-то вроде Hadoop. Но, как правило, мы действительно говорим о больших данных здесь. В наши дни вы уже можете много сделать с одним ПК.
Алгоритм решения этой проблемы закрыт для процесса, который мы изучаем для ручного математического деления, а также для преобразования из десятичной в другую базу, например восьмеричную или шестнадцатеричную, за исключением того, что в двух примерах рассматривается только одно каноническое решение.
Чтобы убедиться, что рекурсия завершена, важно заказать массив данных. Чтобы быть эффективными и ограничивать количество рекурсий, важно также начать с более высоких значений данных.
Конкретно, здесь рекурсивная реализация Java для этой проблемы - с копией вектора результата coeff для каждой рекурсии, как ожидалось в теории.
Import java.util.Arrays; public class Solver { public static void main(String args) { int target_sum = 100; // pre-requisite: sorted values !! int data = new int { 5, 10, 20, 25, 40, 50 }; // result vector, init to 0 int coeff = new int; Arrays.fill(coeff, 0); partialSum(data.length - 1, target_sum, coeff, data); } private static void printResult(int coeff, int data) { for (int i = coeff.length - 1; i >= 0; i--) { if (coeff[i] > 0) { System.out.print(data[i] + " * " + coeff[i] + " "); } } System.out.println(); } private static void partialSum(int k, int sum, int coeff, int data) { int x_k = data[k]; for (int c = sum / x_k; c >= 0; c--) { coeff[k] = c; if (c * x_k == sum) { printResult(coeff, data); continue; } else if (k > 0) { // contextual result in parameters, local to method scope int newcoeff = Arrays.copyOf(coeff, coeff.length); partialSum(k - 1, sum - c * x_k, newcoeff, data); // for loop on "c" goes on with previous coeff content } } } }
Но теперь этот код находится в специальном случае: последний тест значения для каждого коэффициента равен 0, поэтому копия не нужна.
В качестве оценки сложности мы можем использовать максимальную глубину рекурсивных вызовов как data.length * min({ data }) . Конечно, он не будет хорошо масштабироваться, а ограниченным фактором будет память трассировки стека (опция -Xss JVM). Код может выйти из строя с ошибкой для большого набора data .
Чтобы избежать этих недостатков, процесс "прекращения" полезен. Он заключается в замене стека вызовов метода на программный стек для хранения контекста выполнения для последующей обработки. Вот код для этого:
Import java.util.Arrays;
import java.util.ArrayDeque;
import java.util.Queue;
public class NonRecursive
{
// pre-requisite: sorted values !!
private static final int data = new int { 5, 10, 20, 25, 40, 50 };
// Context to store intermediate computation or a solution
static class Context {
int k;
int sum;
int coeff;
Context(int k, int sum, int coeff) {
this.k = k;
this.sum = sum;
this.coeff = coeff;
}
}
private static void printResult(int coeff) {
for (int i = coeff.length - 1; i >= 0; i--) {
if (coeff[i] > 0) {
System.out.print(data[i] + " * " + coeff[i] + " ");
}
}
System.out.println();
}
public static void main(String args)
{
int target_sum = 100;
// result vector, init to 0
int coeff = new int;
Arrays.fill(coeff, 0);
// queue with contexts to process
Queue
С моей точки зрения, трудно быть более эффективным в одном выполнении потока - механизм стека теперь требует копий массива coeff.
Метод Грубой Силы
Полный перебор (или метод «грубой силы» от англ. brute force ) - метод решения задачи путем перебора всех возможных вариантов. Сложность полного перебора зависит от размерности пространства всех возможных решений задачи. Если пространство решений очень велико, то полный перебор может не дать результатов в течение нескольких лет или даже столетий.
Смотреть что такое "Метод Грубой Силы" в других словарях:
Полный перебор (или метод «грубой силы» от англ. brute force) метод решения задачи путем перебора всех возможных вариантов. Сложность полного перебора зависит от размерности пространства всех возможных решений задачи. Если пространство решений… … Википедия
Сортировка простыми обменами, сортировка пузырьком (англ. bubble sort) простой алгоритм сортировки. Для понимания и реализации этот алгоритм простейший, но эффективен он лишь для небольших массивов. Сложность алгоритма: O(n²). Алгоритм… … Википедия
У этого термина существуют и другие значения, см. Перебор. Полный перебор (или метод «грубой силы», англ. brute force) метод решения математических задач. Относится к классу методов поиска решения исчерпыванием всевозможных… … Википедия
Обложка первого издания брошюры «Документы Бейла…» Криптограммы Бейла три зашифрованных сообщения, как то полагается, несущих в себе информацию о местонахождении клада из золота, серебра и драгоценных камней, зарытого якобы на терр … Википедия
Snefru это криптографическая однонаправленная хеш функция, предложенная Ральфом Мерклом. (Само название Snefru, продолжая традиции блочных шифров Khufu и Khafre, также разработанных Ральфом Мерклом, представляет собой имя египетского… … Википедия
Попытка взлома (дешифрования) данных, зашифрованных блочным шифром. К блочным шифрам применимы все основные типы атак, однако существуют некоторые, специфичные лишь для блочных шифров, атаки. Содержание 1 Типы атак 1.1 Общие … Википедия
Нейрокриптография раздел криптографии, изучающий применение стохастических алгоритмов, в частности, нейронных сетей, для шифрования и криптоанализа. Содержание 1 Определение 2 Применение … Википедия
Оптимальный маршрут коммивояжёра через 15 крупнейших городов Германии. Указанный маршрут является самым коротким из всех возможных 43 589 145 600. Задача коммивояжёра (англ. Travelling salesman problem, TSP) (коммивояжёр … Википедия
Криптографическая хеш функция Название N Hash Создан 1990 Опубликован 1990 Размер хеша 128 бит Число раундов 12 или 15 Тип хеш функция N Hash криптографическая … Википедия
Задача коммивояжёра (коммивояжёр бродячий торговец) является одной из самых известных задач комбинаторной оптимизации. Задача заключается в отыскании самого выгодного маршрута, проходящего через указанные города хотя бы по одному разу с… … Википедия
Рис. 11.6. Процедура создания списка Рис. 11.7. Графическое изображение стека Рис. 11.8. Пример бинарного дерева Рис. 11.9. Шаг преобразования дерева к бинарному
Задача сортировки ставится следующим способом. Пусть имеется массив целых или вещественных чисел Требуется переставить элементы этого массива так, чтобы после перестановки они были упорядочены по неубыванию: формула" src="http://hi-edu.ru/e-books/xbook691/files/178-2.gif" border="0" align="absmiddle" alt=" Если числа попарно различны, то говорят об упорядочении по возрастанию или убыванию. В дальнейшем будем рассматривать задачу упорядочения по неубыванию, так как остальные задачи решаются аналогично. Существует множество алгоритмов сортировки, каждый из которых имеет свои характеристики по скорости. Рассмотрим самые простые алгоритмы в порядке увеличения скорости их работы.
Сортировка обменами (пузырьком)
Этот алгоритм считается самым простым и самым медленным. Шаг сортировки состоит в проходе снизу вверх по массиву. При этом просматриваются пары соседних элементов. Если элементы некоторой пары находятся в неправильном порядке, то они меняются местами.
После первого прохода по массиву «вверху» (в начале массива) оказывается самый «легкий» (минимальный) элемент-отсюда аналогия с пузырьком, который всплывает (рис. 11.1
 ). Следующий проход делается до второго сверху элемента, таким образом, второй по величине элемент поднимается на правильную позицию и так далее.
). Следующий проход делается до второго сверху элемента, таким образом, второй по величине элемент поднимается на правильную позицию и так далее.
Проходы делаются по все уменьшающейся нижней части массива до тех пор, пока в ней не останется только один элемент. На этом сортировка заканчивается, так как последовательность упорядочена по возрастанию.
подзаголовок">Сортировка выбором
Сортировка выбором выполняется несколько быстрее, чем сортировка методом пузырька. Алгоритм заключается в следующем: нужно найти элемент массива, имеющий наименьшее значение, переставить его с первым элементом, затем проделать то же самое, начав со второго элемента и т.д. Таким образом, создается отсортированная последовательность путем присоединения к ней одного элемента за другим в правильном порядке. На i-м шаге выбирается наименьший из элементов a[i] ... а[n], и меняем его местами с a[i]. Последовательность шагов изображена на рис. 11.2
 .
.
Вне зависимости от номера текущего шага i, последовательность a...a[i] является упорядоченной. Таким образом, на(n - 1)-м шаге вся последовательность кроме а[n] оказывается отсортированной, а а[n] стоит на последнем месте по праву: все меньшие элементы уже ушли влево.
подзаголовок">Сортировка простыми вставками
Просматривается массив, и каждый новый элемент a[i] вставляется на подходящее место в уже упорядоченную совокупность a,...,a. Это место определяется последовательным сравнением a[i] с упорядоченными элементами a,...,a. Таким образом, в начале массива «вырастает» отсортированная последовательность.
Однако в сортировке пузырьком или выбором можно было четко заявить, что на i-м шаге элементы a...a стоят на правильных местах и никуда более не переместятся. В случае сортировки простыми вставками можно утверждать, что последовательность a...a упорядочена. При этом по ходу алгоритма в нее будут вставляться (см. название метода) все новые элементы.
Рассмотрим действия алгоритма на i-м шаге. Как говорилось выше, последовательность к этому моменту разделена на две части: готовую a...a и неупорядоченную a[i]...a[n].
На следующем, i-м каждом шаге алгоритма, берем a[i] и вставляем на нужное место в готовую часть массива. Поиск подходящего места для очередного элемента входной последовательности осуществляется путем последовательных сравнений с элементом, стоящим перед ним. В зависимости от результата сравнения элемент либо остается на текущем месте (вставка завершена), либо они меняются местами, и процесс повторяется (рис. 11.3
 ).
).
Таким образом, в процессе вставки мы «просеиваем» элемент X к началу массива, останавливаясь в случае, если
- найден элемент, меньший X;
- достигнуто начало последовательности.
опред-е">алгоритмом линейного поиска, когда последовательно проходится весь массив, и текущий элемент массива сравнивается с искомым. В случае совпадения запоминается индекс(ы) найденного элемента.
Однако в задаче поиска может быть множество дополнительных условий. Например, поиск минимального и максимального элемента, поиск подстроки в строке, поиск в массиве, который уже отсортирован, поиск с целью узнать, есть или нет нужный элемент без указания индекса и т.д. Рассмотрим некоторые типовые задачи поиска.
Поиск подстроки в тексте (строке). Алгоритм «грубой силы»
Поиск подстроки в строке осуществляется по заданному образцу, т.е. некоторой последовательности символов, длина которой не превышает длину исходной строки. Задача поиска заключается в том, чтобы определить, содержит ли строка заданный образец и указать место (индекс) в строке, если совпадение найдено.
Алгоритм «грубой силы» является самым простым и самым медленным и заключается в проверке всех позиций текста на предмет совпадения с началом образца. Если начало образца совпадает, то сравнивается следующая буква в образце и в тексте и так далее до полного совпадения с образцом или отличия с ним в очередной букве.
подзаголовок">Алгоритм Бойера-Мура
Простейший вариант алгоритма Бойера-Мура состоит из следующих шагов. На первом шаге строится таблица смещений для искомого образца. Далее совмещается начало строки и образца и начинается проверка с последнего символа образца. Если последний символ образца и соответствующий ему при наложении символ строки не совпадают, образец сдвигается относительно строки на величину, полученную из таблицы смещений, и снова проводится сравнение, начиная с последнего символа образца. Если же символы совпадают, производится сравнение предпоследнего символа образца и т.д. Если все символы образца совпали с наложенными символами строки, значит, найдена подстрока, и поиск окончен. Если же какой-то (не последний) символ образца не совпадает с соответствующим символом строки, мы сдвигаем образец на один символ вправо и снова начинаем проверку с последнего символа. Весь алгоритм выполняется до тех пор, пока либо не будет найдено вхождение искомого образца, либо не будет достигнут конец строки.
Величина сдвига в случае несовпадения последнего символа вычисляется по правилу: сдвиг образца должен быть минимальным - таким, чтобы не пропустить вхождение образца в строке. Если данный символ строки встречается в образце, то образец смещается таким образом, чтобы символ строки совпал с самым правым вхождением этого символа в образце. Если же образец вообще не содержит этого символа, то образец сдвигается на величину, равную его длине так, что первый символ образца накладывается на следующий за проверявшимся символом строки.
Величина смещения для каждого символа образца зависит только от порядка символов в образце, поэтому смещения удобно вычислить заранее и хранить в виде одномерного массива, где каждому символу алфавита соответствует смещение относительно последнего символа образца. Поясним все вышесказанное на простом примере. Пусть есть набор из пяти символов: а, b, с, d, e и нужно найти вхождение образца «abbad» в строке «abeccacbadbabbad». Следующие схемы иллюстрируют все этапы выполнения алгоритма:
формула" src="http://hi-edu.ru/e-books/xbook691/files/ris-page184-1.gif" border="0" align="absmiddle" alt="
Начало поиска. Последний символ образца не совпадает с наложенным символом строки. Сдвигаем образец вправо на 5 позиций:
формула" src="http://hi-edu.ru/e-books/xbook691/files/ris-page185.gif" border="0" align="absmiddle" alt="
Последний символ снова не совпадает с символом строки. В соответствии с таблицей смещений сдвигаем образец на две позиции:
формула" src="http://hi-edu.ru/e-books/xbook691/files/ris-page185-2.gif" border="0" align="absmiddle" alt="
Теперь в соответствии с таблицей сдвигаем образец на одну позицию и получаем искомое вхождение образца:
формула" src="http://hi-edu.ru/e-books/xbook691/files/ris-page185-4.gif" border="0" align="absmiddle" alt="
формула" src="http://hi-edu.ru/e-books/xbook691/files/ris-page186.gif" border="0" align="absmiddle" alt="
Функция BMSearch возвращает позицию первого символа первого вхождения образца Р в строке S. Если последовательность Р в S не найдена, функция возвращает 0 (напомним, что в ObjectPascal нумерация символов в строке String начинается с 1). Параметр StartPos позволяет указать позицию в строке S, с которой следует начинать поиск. Это может быть полезно в том случае, если требуется найти все вхождения Р в S. Для поиска с самого начала строки следует задать StartPos равным 1. Если результат поиска не равен нулю, то для того, чтобы найти следующее вхождение Р в S, нужно задать StartPos равным значению «предыдущий результат плюс длина образца».
Бинарный (двоичный) поиск
Бинарный поиск используется в том случае, если массив, в котором он осуществляется, уже упорядочен.
Переменные Lb и Ub содержат соответственно левую и правую границы отрезка массива, где находится нужный элемент. Поиск всегда начинается с исследования среднего элемента отрезка. Если искомое значение меньше среднего элемента, то нужно перейти к поиску в верхней половине отрезка, где все элементы меньше только что проверенного. Другими словами, значением Ub становится (М-1), на следующей итерации проверяется половина исходного массива. Таким образом, в результате каждой проверки вдвое сужается область поиска. Например, если в массиве 100 чисел, то после первой итерации область поиска уменьшается до 50 чисел, после второй - до 25, после третьей до 13, после четвертой до 7 и т.д..gif" border="0" align="absmiddle" alt="
Динамические структуры данных основаны на использовании указателей и применении стандартных процедур и функций выделения / освобождения памяти в процессе работы программы. Они отличаются от статических структур данных, которые описываются в разделах описания типов и данных. Когда описывается статическая переменная в программе, то при компиляции программы в зависимости от типа переменной выделяется оперативная память. При этом изменить размер выделенной памяти невозможно.
Например, если указан массив
Var S:array of char,
то под него один раз в начале выполнения программ выделяются 10 байтов оперативной памяти.
Динамические структуры характеризуются непостоянством и непредсказуемостью размера (числа элементов) структуры в процессе ее обработки.
Поскольку элементы динамической структуры располагаются по непредсказуемым адресам памяти, адрес элемента такой структуры не может быть вычислен из адреса начального или предыдущего элемента.
Для установления связи между элементами динамической структуры используются указатели, через которые устанавливаются явные связи между элементами. Такое представление данных в памяти называется связным. Элемент динамической структуры состоит из двух полей:
- информационного поля или поля данных, в котором содержатся те данные, ради которых и создается структура; в общем случае информационное поле само является интегрированной структурой: записью, вектором, массивом, другой динамической структурой и т.п.;
- поля связок, в которых содержатся один или несколько указателей, связывающих данный элемент с другими элементами структуры.
Когда связное представление данных применяется для решения прикладной задачи, для конечного пользователя «видимым» делается только содержимое информационного поля, а поле связок используется только программистом-разработчиком.
Достоинства связного представления данных:
- возможность обеспечения значительной изменчивости структур;
- ограничение размера структуры только доступным объемом машинной памяти;
- при изменении логической последовательности элементов структуры требуется не перемещение данных в памяти, а только коррекция указателей;
- большая гибкость структуры.
Вместе с тем связное представление не лишено и недостатков, основные из которых:
Последний недостаток - наиболее серьезный, и именно им ограничивается применимость связного представления данных. Если в смежном представлении данных (массивы) для вычисления адреса любого элемента нам во всех случаях достаточно было номера элемента и информации, содержащейся в дескрипторе структуры, то для связного представления адрес элемента не может быть вычислен из исходных данных. Дескриптор связной структуры содержит один или несколько указателей, позволяющих войти в структуру, далее поиск требуемого элемента выполняется следованием по цепочке указателей от элемента к элементу. Поэтому связное представление практически никогда не применяется в задачах, где логическая структура данных имеет вид вектора или массива - с доступом по номеру элемента, но часто применяется в задачах, где логическая структура требует другой исходной информации доступа (таблицы, списки, деревья и т.д.).
К динамическим структурам, используемым в программировании, относятся:
- динамические массивы (были рассмотрены в теме 6);
- линейные списки;
- стек;
- очередь, дек;
- деревья.
Списком называется упорядоченное множество, состоящее из переменного числа элементов, к которым применимы операции включения, исключения. Список, отражающий отношения соседства между элементами, называется линейным. Длина списка равна числу элементов, содержащихся в нем, список нулевой длины называется пустым. Линейные связные списки являются простейшими динамическими структурами данных.
Графически связи в списках удобно изображать с помощью стрелок, как было показано в разделе описания указателей. Если элемент списка не связан с любым другим, то в поле указателя записывают значение, не указывающее ни на какой элемент (пустой указатель). Такая ссылка в Паскале обозначается Nil, а на схеме обозначается перечеркнутым прямоугольником. Ниже приведена структура односвязного списка
(рис. 11.4
 ), т.е. связь идет от одного элемента списка к другому в одном направлении
. Здесь поле D - это информационное поле, в котором находятся данные (любой допустимый в языке Паскаль тип), поле N (NEXT) - указатель на следующий элемент списка.
), т.е. связь идет от одного элемента списка к другому в одном направлении
. Здесь поле D - это информационное поле, в котором находятся данные (любой допустимый в языке Паскаль тип), поле N (NEXT) - указатель на следующий элемент списка.
Каждый список должен иметь следующие указатели: Head - голова списка, Cur - текущий элемент списка, иногда в односвязных списках также используется указатель Tail - хвост списка (в двухсвяхных списках он используется всегда). Поле указателя последнего элемента списка пустое, в нем находится специальный признак Nil, свидетельствующий о конце списка и обозначаемый перечеркнутым квадратом.
Двухсвязный линейный список отличается от односвязного наличием в каждом узле списка еще одного указателя В (Back), ссылающегося на предыдущий элемент списка (рис. 11.5
 ).
).
Структура данных, соответствующая двухсвязному линейному списку описывается на языке Паскаль следующим образом:
маркер">
Методы разработки алгоритмов n Метод грубой силы («в лоб») n Метод декомпозиции n Метод уменьшения размера задачи n Метод преобразования n Динамическое программирование n Жадные методы n Методы сокращения перебора n … ©Павловская Т. А. (СПб НИУ ИТМО) 1

 Метод грубой силы («в лоб») n Прямой подход к решению задачи, обычно основанный непосредственно на формулировке задачи и определениях используемых ею концепций Пример: вычисление степени числа умножением 1 на это число n раз n Применим практически для любых типов задач n Часто оказывается наиболее простым в применении n Редко дает красивые и эффективные алгоритмы n Стоимость разработки более эффективного алгоритма может оказаться неприемлемой, если требуется решить только несколько экземпляров задачи n Может оказаться полезным для решения небольших по размеру экземпляров задачи. n Может служить мерилом для определения эффективности других алгоритмов ©Павловская Т. А. (СПб НИУ ИТМО) 3
Метод грубой силы («в лоб») n Прямой подход к решению задачи, обычно основанный непосредственно на формулировке задачи и определениях используемых ею концепций Пример: вычисление степени числа умножением 1 на это число n раз n Применим практически для любых типов задач n Часто оказывается наиболее простым в применении n Редко дает красивые и эффективные алгоритмы n Стоимость разработки более эффективного алгоритма может оказаться неприемлемой, если требуется решить только несколько экземпляров задачи n Может оказаться полезным для решения небольших по размеру экземпляров задачи. n Может служить мерилом для определения эффективности других алгоритмов ©Павловская Т. А. (СПб НИУ ИТМО) 3
 n Пример: сортировки выбором и пузырьком 28 -5 ©Павловская Т. А. (СПб НИУ ИТМО) 16 0 29 3 -4 56 4
n Пример: сортировки выбором и пузырьком 28 -5 ©Павловская Т. А. (СПб НИУ ИТМО) 16 0 29 3 -4 56 4
 Исчерпывающий перебор - подход к комбинаторным задачам с позиции грубой силы. Он предполагает: n генерацию всех возможных элементов из области определения задачи n выбор тех из них, которые удовлетворяют ограничениям, накладываемым условием задачи n поиск нужного элемента (например, оптимизирующего значение целевой функции задачи). Примеры: Задача коммивояжера: найти кратчайший путь по Рассмотреть все подмножества данного множества из n предметов, заданным N городам, чтобы каждый город посещался только вычислить общий вес каждого из них для выяснения допустимости, один раз и конечным пунктом оказался исходный. выбрать из допустимых подмножества с максимальным весом. n Получить все возможные маршруты, генерируя все Задача о рюкзаке: дано N предметов заданного веса и стоимости рюкзак, выдерживающий вес W. Загрузить рюкзак перестановки n - 1 промежуточных городов, вычисляя с максимальной стоимостью. длину соответствующих путей и находя кратчайший из них. Это - NP-сложные задачи (не известен алгоритм, решающий их за полиномиальное время). n ©Павловская Т. А. (СПб НИУ ИТМО) 5
Исчерпывающий перебор - подход к комбинаторным задачам с позиции грубой силы. Он предполагает: n генерацию всех возможных элементов из области определения задачи n выбор тех из них, которые удовлетворяют ограничениям, накладываемым условием задачи n поиск нужного элемента (например, оптимизирующего значение целевой функции задачи). Примеры: Задача коммивояжера: найти кратчайший путь по Рассмотреть все подмножества данного множества из n предметов, заданным N городам, чтобы каждый город посещался только вычислить общий вес каждого из них для выяснения допустимости, один раз и конечным пунктом оказался исходный. выбрать из допустимых подмножества с максимальным весом. n Получить все возможные маршруты, генерируя все Задача о рюкзаке: дано N предметов заданного веса и стоимости рюкзак, выдерживающий вес W. Загрузить рюкзак перестановки n - 1 промежуточных городов, вычисляя с максимальной стоимостью. длину соответствующих путей и находя кратчайший из них. Это - NP-сложные задачи (не известен алгоритм, решающий их за полиномиальное время). n ©Павловская Т. А. (СПб НИУ ИТМО) 5

 Метод декомпозиции Он же - метод «разделяй и властвуй»: n Экземпляр задачи разбивается на несколько меньших экземпляров той же задачи, в идеале - одинакового размера. n Решаются меньшие экземпляры задачи (обычно рекурсивно, хотя иногда для небольших экземпляров применяется какой-нибудь другой алгоритм). n При необходимости решение исходной задачи находится путем комбинации решений меньших экземпляров. Метод декомпозиции идеально подходит для параллельных вычислений. ©Павловская Т. А. (СПб НИУ ИТМО) 7
Метод декомпозиции Он же - метод «разделяй и властвуй»: n Экземпляр задачи разбивается на несколько меньших экземпляров той же задачи, в идеале - одинакового размера. n Решаются меньшие экземпляры задачи (обычно рекурсивно, хотя иногда для небольших экземпляров применяется какой-нибудь другой алгоритм). n При необходимости решение исходной задачи находится путем комбинации решений меньших экземпляров. Метод декомпозиции идеально подходит для параллельных вычислений. ©Павловская Т. А. (СПб НИУ ИТМО) 7
 Рекуррентное уравнение декомпозиции n В общем случае экземпляр задачи размера n может быть разделен на несколько экземпляров размером n/b, а из которых требуется решить. n Обобщенное рекуррентное уравнение декомпозиции: (1) n для упрощения принято, что размер n равен степени b. n Порядок роста зависит от a, b и f. ©Павловская Т. А. (СПб НИУ ИТМО) 8
Рекуррентное уравнение декомпозиции n В общем случае экземпляр задачи размера n может быть разделен на несколько экземпляров размером n/b, а из которых требуется решить. n Обобщенное рекуррентное уравнение декомпозиции: (1) n для упрощения принято, что размер n равен степени b. n Порядок роста зависит от a, b и f. ©Павловская Т. А. (СПб НИУ ИТМО) 8
 Основная теорема декомпозиции (1) n Можно указать класс эффективности алгоритма, не решая само рекуррентное уравнение. n Этот подход позволяет установить порядок роста решения, не определяя неизвестные множители. ©Павловская Т. А. (СПб НИУ ИТМО) 9
Основная теорема декомпозиции (1) n Можно указать класс эффективности алгоритма, не решая само рекуррентное уравнение. n Этот подход позволяет установить порядок роста решения, не определяя неизвестные множители. ©Павловская Т. А. (СПб НИУ ИТМО) 9
 Сортировка слиянием Сортирует заданный массив путем его разделения на две половины, рекурсивной сортировки каждой половины и слияния двух отсортированных половин в один отсортированный массив: Mergesort (A) if n>1 Первая половина А -> в массив В Вторая половина А -> в массив С Mergesort(B) Mergesort(C) Меrgе(В, С, А) // слить ©Павловская Т. А. (СПб НИУ ИТМО) 10
Сортировка слиянием Сортирует заданный массив путем его разделения на две половины, рекурсивной сортировки каждой половины и слияния двух отсортированных половин в один отсортированный массив: Mergesort (A) if n>1 Первая половина А -> в массив В Вторая половина А -> в массив С Mergesort(B) Mergesort(C) Меrgе(В, С, А) // слить ©Павловская Т. А. (СПб НИУ ИТМО) 10
Src="http://present5.com/presentation/54441564_438337950/image-11.jpg" alt="Mergesort (A) if n>1 Первая половина А -> в массив В Вторая половина А"> Mergesort (A) if n>1 Первая половина А -> в массив В Вторая половина А > в массив С Mergesort(B) Mergesort(C) Меrgе(В, С, А) ©Павловская Т. А. (СПб НИУ ИТМО) 11
 Слияние массивов n Два индекса массивов после инициализации указывают на первые элементы сливаемых массивов. n Элементы сравниваются, и меньший из них добавляется в новый массив. n Индекс меньшего элемента увеличивается (он указывает на элемент, непосредственно следующий за только что скопированным). Эта операция повторяется до тех пор, пока не будет исчерпан один из сливаемых массивов. Оставшиеся элементы второго массива добавляются в конец нового массива. ©Павловская Т. А. (СПб НИУ ИТМО) 12
Слияние массивов n Два индекса массивов после инициализации указывают на первые элементы сливаемых массивов. n Элементы сравниваются, и меньший из них добавляется в новый массив. n Индекс меньшего элемента увеличивается (он указывает на элемент, непосредственно следующий за только что скопированным). Эта операция повторяется до тех пор, пока не будет исчерпан один из сливаемых массивов. Оставшиеся элементы второго массива добавляются в конец нового массива. ©Павловская Т. А. (СПб НИУ ИТМО) 12
 Анализ сортировки слиянием n Пусть длина файла является степенью 2. n Количество сравнений ключей: C(n) = 2*C(n/2) + Cmerge (n) n > 1, C(1)=0 n Cmerge (n) = n-1 в худшем случае (кол-во сравнений ключей при слиянии) n В худшем случае Cw: d=1 a=2 b=2 Cw(n) = 2*Cw (n/2) +n-1 Cw (n) (n log n) – по осн. теореме ©Павловская Т. А. (СПб НИУ ИТМО) (1) 13
Анализ сортировки слиянием n Пусть длина файла является степенью 2. n Количество сравнений ключей: C(n) = 2*C(n/2) + Cmerge (n) n > 1, C(1)=0 n Cmerge (n) = n-1 в худшем случае (кол-во сравнений ключей при слиянии) n В худшем случае Cw: d=1 a=2 b=2 Cw(n) = 2*Cw (n/2) +n-1 Cw (n) (n log n) – по осн. теореме ©Павловская Т. А. (СПб НИУ ИТМО) (1) 13
 n Количество сравнений ключей, выполняемых сортировкой слиянием, в худшем случае весьма близко к теоретическому минимуму количества сравнений для любого алгоритма сортировки, основанного на сравнениях. n Основной недостаток сортировки слиянием - необходимость дополнительной памяти, количество которой линейно пропорционально размеру входных данных. ©Павловская Т. А. (СПб НИУ ИТМО) 14
n Количество сравнений ключей, выполняемых сортировкой слиянием, в худшем случае весьма близко к теоретическому минимуму количества сравнений для любого алгоритма сортировки, основанного на сравнениях. n Основной недостаток сортировки слиянием - необходимость дополнительной памяти, количество которой линейно пропорционально размеру входных данных. ©Павловская Т. А. (СПб НИУ ИТМО) 14
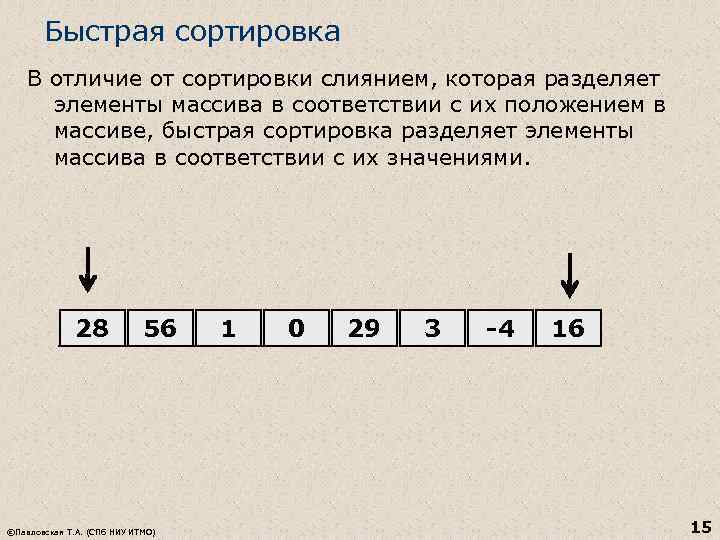 Быстрая сортировка В отличие от сортировки слиянием, которая разделяет элементы массива в соответствии с иx положением в массиве, быстрая сортировка разделяет элементы массива в соответствии с их значениями. 28 56 ©Павловская Т. А. (СПб НИУ ИТМО) 1 0 29 3 -4 16 15
Быстрая сортировка В отличие от сортировки слиянием, которая разделяет элементы массива в соответствии с иx положением в массиве, быстрая сортировка разделяет элементы массива в соответствии с их значениями. 28 56 ©Павловская Т. А. (СПб НИУ ИТМО) 1 0 29 3 -4 16 15
 Описание алгоритма n Выбираем опорный элемент n Выполняем перестановку элементов для получения разбиения, когда все элементы до некоторой позиции s не превышают элемента A [s], а элементы после позиции s не меньше него. n Очевидно, что после разбиения A [s] находится в окончательной позиции, и мы можем сортировать два подмассива элементов до и после A [s] независимо (тем же или другим методом) ©Павловская Т. А. (СПб НИУ ИТМО) 16
Описание алгоритма n Выбираем опорный элемент n Выполняем перестановку элементов для получения разбиения, когда все элементы до некоторой позиции s не превышают элемента A [s], а элементы после позиции s не меньше него. n Очевидно, что после разбиения A [s] находится в окончательной позиции, и мы можем сортировать два подмассива элементов до и после A [s] независимо (тем же или другим методом) ©Павловская Т. А. (СПб НИУ ИТМО) 16
 Процедура перестановки элементов n Эффективный метод, основанный на двух проходах подмассива - слева направо и справа налево. При каждом проходе элементы сравниваются с опорным. n Проход слева направо (i) пропускает элементы, меньшие опорного, и останавливается на первом элементе, не меньшем опорного. n Проход справа налево (j) пропускает элементы, большие опорного, и останавливается на первом элементе, не превышающем опорный. n Если индексы сканирования не пересеклись, обмениваем найденные элементы местами и продолжаем проходы. n Если индексы пересеклись, обмениваем опорный элемент с Aj ©Павловская Т. А. (СПб НИУ ИТМО) 17
Процедура перестановки элементов n Эффективный метод, основанный на двух проходах подмассива - слева направо и справа налево. При каждом проходе элементы сравниваются с опорным. n Проход слева направо (i) пропускает элементы, меньшие опорного, и останавливается на первом элементе, не меньшем опорного. n Проход справа налево (j) пропускает элементы, большие опорного, и останавливается на первом элементе, не превышающем опорный. n Если индексы сканирования не пересеклись, обмениваем найденные элементы местами и продолжаем проходы. n Если индексы пересеклись, обмениваем опорный элемент с Aj ©Павловская Т. А. (СПб НИУ ИТМО) 17
 Эффективность быстрой сортировки n Наилучший случай: все разбиения оказываются посередине соответствующих подмассивов n В наихудшем случае все разбиения оказываются такими, что один из подмассивов пуст, а размер второго на 1 меньше размера разбиваемого массива (зависимость квадратичная). n В среднем случае считаем, что разбиение может выполняться в каждой позиции с одинаковой вероятностью: Cavg 2 n ln n 1, 38 n log 2 n ©Павловская Т. А. (СПб НИУ ИТМО) 18
Эффективность быстрой сортировки n Наилучший случай: все разбиения оказываются посередине соответствующих подмассивов n В наихудшем случае все разбиения оказываются такими, что один из подмассивов пуст, а размер второго на 1 меньше размера разбиваемого массива (зависимость квадратичная). n В среднем случае считаем, что разбиение может выполняться в каждой позиции с одинаковой вероятностью: Cavg 2 n ln n 1, 38 n log 2 n ©Павловская Т. А. (СПб НИУ ИТМО) 18
 Улучшения алгоритма n улучшенные методы выбора опорного элемента n переключение на более простую сортировку для малых подмассивов n удаление рекурсии Все вместе эти улучшения могут снизить время работы алгоритма на 20 -25% (Р. Седжвик) ©Павловская Т. А. (СПб НИУ ИТМО) 19
Улучшения алгоритма n улучшенные методы выбора опорного элемента n переключение на более простую сортировку для малых подмассивов n удаление рекурсии Все вместе эти улучшения могут снизить время работы алгоритма на 20 -25% (Р. Седжвик) ©Павловская Т. А. (СПб НИУ ИТМО) 19
 Обход бинарного дерева Это еще один пример применения метода декомпозиции n При обходе в прямом порядке сначала посещается корень дерева, а затем левое и правое поддеревья. n При симметричном обходе корень посещается после левого поддерева, но перед посещением правого. n При обходе в обратном порядке корень посещается после левого и правого поддеревьев. ©Павловская Т. А. (СПб НИУ ИТМО) 20
Обход бинарного дерева Это еще один пример применения метода декомпозиции n При обходе в прямом порядке сначала посещается корень дерева, а затем левое и правое поддеревья. n При симметричном обходе корень посещается после левого поддерева, но перед посещением правого. n При обходе в обратном порядке корень посещается после левого и правого поддеревьев. ©Павловская Т. А. (СПб НИУ ИТМО) 20
 Обход дерева procedure print_tree(дерево); begin print_tree(левое_поддерево) посещение корня print_tree(правое_поддерево) end; 1 6 8 10 20 ©Павловская Т. А. (СПб. ГУ ИТМО) 21 25 30 21
Обход дерева procedure print_tree(дерево); begin print_tree(левое_поддерево) посещение корня print_tree(правое_поддерево) end; 1 6 8 10 20 ©Павловская Т. А. (СПб. ГУ ИТМО) 21 25 30 21

 Метод уменьшения размера задачи Основан на использовании связи между решением данного экземпляра задачи и решением меньшего экземпляра той же задачи. Если такая связь установлена, ее можно использовать либо сверху вниз (рекурсивно), либо снизу вверх (без рекурсии). (пример – возведение числа в степень) Имеется три основных варианта метода уменьшения размера: n уменьшение на постоянную величину (обычно на 1); n уменьшение на постоянный множитель (обычно в 2 раза); n уменьшение переменного размера. ©Павловская Т. А. (СПб НИУ ИТМО) 23
Метод уменьшения размера задачи Основан на использовании связи между решением данного экземпляра задачи и решением меньшего экземпляра той же задачи. Если такая связь установлена, ее можно использовать либо сверху вниз (рекурсивно), либо снизу вверх (без рекурсии). (пример – возведение числа в степень) Имеется три основных варианта метода уменьшения размера: n уменьшение на постоянную величину (обычно на 1); n уменьшение на постоянный множитель (обычно в 2 раза); n уменьшение переменного размера. ©Павловская Т. А. (СПб НИУ ИТМО) 23
 Сортировка вставкой Предположим, что задача сортировки массива размерностью n-1 решена. Тогда остается вставить An в нужное место: n Просматривая массив слева направо n Просматривая массив справа налево n Используя бинарный поиск места вставки n Хотя сортировка вставкой основана на рекурсивном подходе, более эффективной будет ее реализация снизу вверх (итеративная). ©Павловская Т. А. (СПб НИУ ИТМО) 24
Сортировка вставкой Предположим, что задача сортировки массива размерностью n-1 решена. Тогда остается вставить An в нужное место: n Просматривая массив слева направо n Просматривая массив справа налево n Используя бинарный поиск места вставки n Хотя сортировка вставкой основана на рекурсивном подходе, более эффективной будет ее реализация снизу вверх (итеративная). ©Павловская Т. А. (СПб НИУ ИТМО) 24
 Реализация на псевдокоде for i = 1 to n - 1 do v = 0 and A[j] > v do A
Реализация на псевдокоде for i = 1 to n - 1 do v = 0 and A[j] > v do A
 Эффективность сортировки вставкой n Наихудший случай: выполняется столько же сравнений, сколько и в сортировке выбором n Наилучший случай (для изначально отсортированного массива): сравнение выполняется только 1 раз для каждого прохода внешнего цикла n Средний случай (случайный массив): выполняется в ~2 раза меньше сравнений, чем в случае убывающего массива. Т. о. , средний случай в 2 раза лучше наихудшего. Вкупе с превосходной производительностью для почти отсортированных массивов это выделяет сортировку вставкой из других элементарных (выбором и пузырьком) алгоритмов n Модификация метода – вставка одновременно нескольких элементов, которые перед вставкой сортируются. n Расширение сортировки вставкой - сортировка Шелла, дает еще лучший алгоритм для сортировки достаточно больших файлов. ©Павловская Т. А. (СПб НИУ ИТМО) 26
Эффективность сортировки вставкой n Наихудший случай: выполняется столько же сравнений, сколько и в сортировке выбором n Наилучший случай (для изначально отсортированного массива): сравнение выполняется только 1 раз для каждого прохода внешнего цикла n Средний случай (случайный массив): выполняется в ~2 раза меньше сравнений, чем в случае убывающего массива. Т. о. , средний случай в 2 раза лучше наихудшего. Вкупе с превосходной производительностью для почти отсортированных массивов это выделяет сортировку вставкой из других элементарных (выбором и пузырьком) алгоритмов n Модификация метода – вставка одновременно нескольких элементов, которые перед вставкой сортируются. n Расширение сортировки вставкой - сортировка Шелла, дает еще лучший алгоритм для сортировки достаточно больших файлов. ©Павловская Т. А. (СПб НИУ ИТМО) 26

 Генерация комбинаторных объектов n Наиболее важными типами комбинаторных объектов являются перестановки, сочетания и подмножества данного множества. n Обычно они возникают в задачах, требующих рассмотрения различных вариантов выбора. n Кроме того, существуют понятия размещения и разбиения. ©Павловская Т. А. (СПб НИУ ИТМО) 28
Генерация комбинаторных объектов n Наиболее важными типами комбинаторных объектов являются перестановки, сочетания и подмножества данного множества. n Обычно они возникают в задачах, требующих рассмотрения различных вариантов выбора. n Кроме того, существуют понятия размещения и разбиения. ©Павловская Т. А. (СПб НИУ ИТМО) 28
 Генерация перестановок Число перестановок n Пусть дан n-элементный набор (множество). n На первом месте в перестановке может стоять любой элемент, то есть существует n способов выбора первого элемента. n Осталось (n-1) элементов для выбора второго элемента в перестановке (существует (n-1) способов выбора второго элемента). n Осталось (n-2) элемента для выбора третьего элемента в перестановке, и т. д. n Итого, n-элементный упорядоченный набор можно получить: способами ©Павловская Т. А. (СПб НИУ ИТМО) 29
Генерация перестановок Число перестановок n Пусть дан n-элементный набор (множество). n На первом месте в перестановке может стоять любой элемент, то есть существует n способов выбора первого элемента. n Осталось (n-1) элементов для выбора второго элемента в перестановке (существует (n-1) способов выбора второго элемента). n Осталось (n-2) элемента для выбора третьего элемента в перестановке, и т. д. n Итого, n-элементный упорядоченный набор можно получить: способами ©Павловская Т. А. (СПб НИУ ИТМО) 29
 Применение метода уменьшения размера к задаче получения всех перестановок n Для простоты положим, что множество переставляемых элементов - это множество целых чисел от 1 до n. n Задача меньшего на единицу размера состоит в генерации всех (n - 1)! перестановок. n Полагая, что она решена, мы можем получить решение большей задачи путем вставки n в каждую из n возможных позиций среди элементов каждой из перестановок n - 1 элементов. n Все получаемые таким образом перестановки будут различны, а их общее количество: n(n- 1)! = n! n Можно вставлять n в ранее сгенерированные перестановки слева направо или справа налево. Выгодно начинать справа налево и изменять направление всякий раз при переходе к новой перестановке множества {1, . . . , n - 1}. ©Павловская Т. А. (СПб НИУ ИТМО) 30
Применение метода уменьшения размера к задаче получения всех перестановок n Для простоты положим, что множество переставляемых элементов - это множество целых чисел от 1 до n. n Задача меньшего на единицу размера состоит в генерации всех (n - 1)! перестановок. n Полагая, что она решена, мы можем получить решение большей задачи путем вставки n в каждую из n возможных позиций среди элементов каждой из перестановок n - 1 элементов. n Все получаемые таким образом перестановки будут различны, а их общее количество: n(n- 1)! = n! n Можно вставлять n в ранее сгенерированные перестановки слева направо или справа налево. Выгодно начинать справа налево и изменять направление всякий раз при переходе к новой перестановке множества {1, . . . , n - 1}. ©Павловская Т. А. (СПб НИУ ИТМО) 30
 Пример (восходящая генерация перестановок) n 12 21 n 123 132 312 321 231 213 ©Павловская Т. А. (СПб НИУ ИТМО) 31
Пример (восходящая генерация перестановок) n 12 21 n 123 132 312 321 231 213 ©Павловская Т. А. (СПб НИУ ИТМО) 31
 Алгоритм Джонсона-Троттера Вводится понятие мобильного элемента. С каждым элементом связывается стрелка, элемент считается мобильным, если стрелка указывает на меньший соседний элемент. n Инициализируем первую перестановку значением 1 2. . . n (все стрелки влево) n while имеется мобильное число к do n Находим наибольшее мобильное число к Меняем местами к и соседнее число, на которое указывает стрелка к n n Меняем направление стрелок у всех чисел, больших к ©Павловская Т. А. (СПб НИУ ИТМО) 32
Алгоритм Джонсона-Троттера Вводится понятие мобильного элемента. С каждым элементом связывается стрелка, элемент считается мобильным, если стрелка указывает на меньший соседний элемент. n Инициализируем первую перестановку значением 1 2. . . n (все стрелки влево) n while имеется мобильное число к do n Находим наибольшее мобильное число к Меняем местами к и соседнее число, на которое указывает стрелка к n n Меняем направление стрелок у всех чисел, больших к ©Павловская Т. А. (СПб НИУ ИТМО) 32
 Лексикографический порядок n Пусть есть первая перестановка (например, 1234). n Для нахождения каждой следующей: 1. Cканируем текущую перестановку справа налево в поисках первой пары соседних элементов таких, что a[i]
Лексикографический порядок n Пусть есть первая перестановка (например, 1234). n Для нахождения каждой следующей: 1. Cканируем текущую перестановку справа налево в поисках первой пары соседних элементов таких, что a[i]
 Пример для осознания алгоритма 1234 1243 1324 1342 1423 1432 2134 2143 2314 2341 2413 2431 3124 3142 3214 3241 3412 3421 4123 4132 4213 4231 4312 4321 ©Павловская Т. А. (СПб НИУ ИТМО) 34
Пример для осознания алгоритма 1234 1243 1324 1342 1423 1432 2134 2143 2314 2341 2413 2431 3124 3142 3214 3241 3412 3421 4123 4132 4213 4231 4312 4321 ©Павловская Т. А. (СПб НИУ ИТМО) 34
 Число всех перестановок из n элементов Р(n) = n! ©Павловская Т. А. (СПб НИУ ИТМО) 35
Число всех перестановок из n элементов Р(n) = n! ©Павловская Т. А. (СПб НИУ ИТМО) 35
 Подмножества n Множество A является подмножеством множества B, если любой элемент, принадлежащий A, также принадлежит B: A B или A B n Любое множество является своим подмножеством. Пустое множество является подмножеством любого множества. n Множество всех подмножества обозначается 2 A (еще его называют power set, множество-степень, степень множества, булеан, показательное множество). n Число подмножеств конечного множества, состоящего из n элементов, равно 2 n (доказательство см. в Википедии) ©Павловская Т. А. (СПб НИУ ИТМО) 36
Подмножества n Множество A является подмножеством множества B, если любой элемент, принадлежащий A, также принадлежит B: A B или A B n Любое множество является своим подмножеством. Пустое множество является подмножеством любого множества. n Множество всех подмножества обозначается 2 A (еще его называют power set, множество-степень, степень множества, булеан, показательное множество). n Число подмножеств конечного множества, состоящего из n элементов, равно 2 n (доказательство см. в Википедии) ©Павловская Т. А. (СПб НИУ ИТМО) 36
 Генерация всех подмножества n Применим метод уменьшения размера задачи на 1. n Все подмножества А = {a 1, . . . , аn} можно разделить на две группы - которые содержат элемент аn и которые его не содержат. n Первая группа – это все подмножества {a 1, . . . , an-1}; все элементы второй группы можно получить путем добавления элемента аn к подмножествам первой группы. {a 1} {a 2} {a 1, a 2} {a 3} {a 1, a 3} {a 2, a 3} {a 1, a 2, a 3} Удобно поставить в соответствие элементам множества битовые строки: 000 001 010 011 100 101 110 111 n Иные порядки: плотный; код Грея: n 000 001 010 111 100 ©Павловская Т. А. (СПб НИУ ИТМО) 37
Генерация всех подмножества n Применим метод уменьшения размера задачи на 1. n Все подмножества А = {a 1, . . . , аn} можно разделить на две группы - которые содержат элемент аn и которые его не содержат. n Первая группа – это все подмножества {a 1, . . . , an-1}; все элементы второй группы можно получить путем добавления элемента аn к подмножествам первой группы. {a 1} {a 2} {a 1, a 2} {a 3} {a 1, a 3} {a 2, a 3} {a 1, a 2, a 3} Удобно поставить в соответствие элементам множества битовые строки: 000 001 010 011 100 101 110 111 n Иные порядки: плотный; код Грея: n 000 001 010 111 100 ©Павловская Т. А. (СПб НИУ ИТМО) 37
 Генерация кодов Грея n Код Грея для n бит может быть рекурсивно построен на основе кода для n– 1 бит путём: n записывания кодов в обратном порядке n конкатенации исходного и перевёрнутого списков n дописывания 0 в начало каждого кода в исходном списке и 1 в начало кодов в перевёрнутом списке. Пример: n Коды для n = 2 бит: 00, 01, 10 n Перевёрнутый список кодов: 10, 11, 00 n Объединённый список: 00, 01, 10, 11, 00 n К начальному списку дописаны нули: 000, 001, 010, 11, 00 n К перевёрнутому списку дописаны единицы: 000, 001, 010, 111, 100 ©Павловская Т. А. (СПб НИУ ИТМО) 38
Генерация кодов Грея n Код Грея для n бит может быть рекурсивно построен на основе кода для n– 1 бит путём: n записывания кодов в обратном порядке n конкатенации исходного и перевёрнутого списков n дописывания 0 в начало каждого кода в исходном списке и 1 в начало кодов в перевёрнутом списке. Пример: n Коды для n = 2 бит: 00, 01, 10 n Перевёрнутый список кодов: 10, 11, 00 n Объединённый список: 00, 01, 10, 11, 00 n К начальному списку дописаны нули: 000, 001, 010, 11, 00 n К перевёрнутому списку дописаны единицы: 000, 001, 010, 111, 100 ©Павловская Т. А. (СПб НИУ ИТМО) 38
 K-элементные подмножества n Количество k-элементных подмножества n (0 k n) называется числом сочетаний (биномиальным коэффициентом): n Прямое решение неэффективно из-за быстрого роста факториала. n Как правило, генерацию k-элементных подмножеств проводят в лексикографическом порядке (для любых двух подмножеств первым генерируется то, из индексов элементов которого можно составить меньшее k-значное число в n-ричной системе счисления). n Метод: n первым элементом подмножества мощности k может быть любой из элементов, начиная с первого и заканчивая (n-k+1)-ым. n После того, как индекс первого элемента подмножества зафиксирован, остается выбрать k-1 элемент из элементов с индексами, большими чем у первого. n Далее аналогично, сводя задачу к меньшей размерности до тех пор, пока на низшем уровне рекурсии не будет выбран последний элемент, после чего выбранное подмножество можно распечатать или обработать. ©Павловская Т. А. (СПб НИУ ИТМО) 39
K-элементные подмножества n Количество k-элементных подмножества n (0 k n) называется числом сочетаний (биномиальным коэффициентом): n Прямое решение неэффективно из-за быстрого роста факториала. n Как правило, генерацию k-элементных подмножеств проводят в лексикографическом порядке (для любых двух подмножеств первым генерируется то, из индексов элементов которого можно составить меньшее k-значное число в n-ричной системе счисления). n Метод: n первым элементом подмножества мощности k может быть любой из элементов, начиная с первого и заканчивая (n-k+1)-ым. n После того, как индекс первого элемента подмножества зафиксирован, остается выбрать k-1 элемент из элементов с индексами, большими чем у первого. n Далее аналогично, сводя задачу к меньшей размерности до тех пор, пока на низшем уровне рекурсии не будет выбран последний элемент, после чего выбранное подмножество можно распечатать или обработать. ©Павловская Т. А. (СПб НИУ ИТМО) 39
 Пример: сочетания из 6 по 3 #include const int N = 6, K = 3; int a[K]; void rec(int i) { if (i == K) { for (int j = 0; j 0 ? a + 1: 1); a[i]
Пример: сочетания из 6 по 3 #include const int N = 6, K = 3; int a[K]; void rec(int i) { if (i == K) { for (int j = 0; j 0 ? a + 1: 1); a[i]
 Свойства сочетаний n каждому n-элементному подмножеству данного элементного множества соответствует одно и только одно n-k-элементное подмножество того же множества: n ©Павловская Т. А. (СПб НИУ ИТМО) 41
Свойства сочетаний n каждому n-элементному подмножеству данного элементного множества соответствует одно и только одно n-k-элементное подмножество того же множества: n ©Павловская Т. А. (СПб НИУ ИТМО) 41


 Размещения n Размещением из n элементов по m называется последовательность, состоящая из m различных элементов некоторого n-элементного множества (комбинации, которые составлены из данных n элементов по m элементов и отличаются либо самими элементами, либо порядком элементов) Различие в определениях сочетаний и размещений: n Сочетание – подмножество, содержащее m элементов из n (порядок элементов не важен). n Размещение – это последовательность, содержащая m элементов из n (порядок элементов важен). При формировании последовательности важен порядок следования элементов, а при формировании подмножества порядок не важен. ©Павловская Т. А. (СПб. ГУ ИТМО) 44
Размещения n Размещением из n элементов по m называется последовательность, состоящая из m различных элементов некоторого n-элементного множества (комбинации, которые составлены из данных n элементов по m элементов и отличаются либо самими элементами, либо порядком элементов) Различие в определениях сочетаний и размещений: n Сочетание – подмножество, содержащее m элементов из n (порядок элементов не важен). n Размещение – это последовательность, содержащая m элементов из n (порядок элементов важен). При формировании последовательности важен порядок следования элементов, а при формировании подмножества порядок не важен. ©Павловская Т. А. (СПб. ГУ ИТМО) 44
 Число размещений n Число размещений из n по m: Пример 1: Сколько существует двузначных чисел, в которых цифра десятков и цифра единиц различны и нечетны? Основное множество: {1, 3, 5, 7, 9} – нечетные цифры, n=5 n Соединение – двузначное число m=2, порядок важен, значит, это размещение «из пяти по два» . n Перестановки можно считать частным случаем размещений при m=n Пример 2: Сколькими способами можно составить флаг, состоящий из трех горизонтальных полос различных цветов, если имеется материал пяти цветов? ©Павловская Т. А. (СПб НИУ ИТМО) 45
Число размещений n Число размещений из n по m: Пример 1: Сколько существует двузначных чисел, в которых цифра десятков и цифра единиц различны и нечетны? Основное множество: {1, 3, 5, 7, 9} – нечетные цифры, n=5 n Соединение – двузначное число m=2, порядок важен, значит, это размещение «из пяти по два» . n Перестановки можно считать частным случаем размещений при m=n Пример 2: Сколькими способами можно составить флаг, состоящий из трех горизонтальных полос различных цветов, если имеется материал пяти цветов? ©Павловская Т. А. (СПб НИУ ИТМО) 45
 Размещения с повторениями n Размещения с повторениями из n элементов множества Е={a 1, a 2, . . . , an} по k - всякая конечная последовательность, состоящая из k элементов данного множества Е. n Два размещения с повторениями считаются различными, если хотя бы на одном месте они имеют различные элементы множества Е. n Число различных размещений с повторениями из n по k равно nk. ©Павловская Т. А. (СПб НИУ ИТМО) 46
Размещения с повторениями n Размещения с повторениями из n элементов множества Е={a 1, a 2, . . . , an} по k - всякая конечная последовательность, состоящая из k элементов данного множества Е. n Два размещения с повторениями считаются различными, если хотя бы на одном месте они имеют различные элементы множества Е. n Число различных размещений с повторениями из n по k равно nk. ©Павловская Т. А. (СПб НИУ ИТМО) 46
 Разбиение множеств n Разбиение множества - это представление его в виде объединения произвольного количества попарно непересекающихся подмножеств. n Количество неупорядоченных разбиений n-элементного множества на k частей - число Стирлинга 2 -го рода: n Количество упорядоченных разбиений n-элементного множества на m частей фиксированного размера – мультиномиальный коэффициент: n Количество всех неупорядоченных разбиений n-элементного множества задается числом Белла: ©Павловская Т. А. (СПб НИУ ИТМО) 47
Разбиение множеств n Разбиение множества - это представление его в виде объединения произвольного количества попарно непересекающихся подмножеств. n Количество неупорядоченных разбиений n-элементного множества на k частей - число Стирлинга 2 -го рода: n Количество упорядоченных разбиений n-элементного множества на m частей фиксированного размера – мультиномиальный коэффициент: n Количество всех неупорядоченных разбиений n-элементного множества задается числом Белла: ©Павловская Т. А. (СПб НИУ ИТМО) 47
 Метод уменьшения на постоянный множитель n Пример: бинарный поиск n Подобные алгоритмы логарифмические и, будучи очень быстрыми, встречаются достаточно редко. Метод уменьшения на переменный множитель n Примеры: поиск и вставка в бинарное дерево поиска, интерполяционный поиск: ©Павловская Т. А. (СПб. ГУ ИТМО) 48
Метод уменьшения на постоянный множитель n Пример: бинарный поиск n Подобные алгоритмы логарифмические и, будучи очень быстрыми, встречаются достаточно редко. Метод уменьшения на переменный множитель n Примеры: поиск и вставка в бинарное дерево поиска, интерполяционный поиск: ©Павловская Т. А. (СПб. ГУ ИТМО) 48
 Анализ эффективности n Интерполяционный поиск в среднем требует менее log 2 n+1 сравнений ключей при поиске в списке из n случайных значений. n Эта функция растет настолько медленно, что для всех реальных практических значений n ее можно считать константой. n Однако в наихудшем случае интерполяционный поиск вырождается в линейный, который рассматривается как наихудший из возможных. n Интерполяционный поиск лучше использовать для файлов большого размера и для приложений, в которых сравнение или обращение к данным - дорогостоящая операция. ©Павловская Т. А. (СПб НИУ ИТМО) 49
Анализ эффективности n Интерполяционный поиск в среднем требует менее log 2 n+1 сравнений ключей при поиске в списке из n случайных значений. n Эта функция растет настолько медленно, что для всех реальных практических значений n ее можно считать константой. n Однако в наихудшем случае интерполяционный поиск вырождается в линейный, который рассматривается как наихудший из возможных. n Интерполяционный поиск лучше использовать для файлов большого размера и для приложений, в которых сравнение или обращение к данным - дорогостоящая операция. ©Павловская Т. А. (СПб НИУ ИТМО) 49
 Метод преобразования n Состоит в том, что экземпляр задачи преобразуется в другой, по той или иной причине легче поддающийся решению. n Имеется три основных варианта этого метода: ©Павловская Т. А. (СПб НИУ ИТМО) 50
Метод преобразования n Состоит в том, что экземпляр задачи преобразуется в другой, по той или иной причине легче поддающийся решению. n Имеется три основных варианта этого метода: ©Павловская Т. А. (СПб НИУ ИТМО) 50
 Пример 1: проверка единственности элементов массива n Алгоритм на основе грубой силы попарно сравнивает все элементы, пока не будут найдены два одинаковых либо пока не будут пересмотрены все возможные пары. В наихудшем случае эффективность квадратична. n К решению задачи можно подойти и по-другому - сначала отсортировать массив, а затем сравнивать только последовательные элементы. n Время работы алгоритма - сумма времени сортировки и времени на проверку соседних элементов. n Если воспользоваться хорошим алгоритмом сортировки, весь алгоритм проверки единственности элементов массива также будет иметь эффективность О (n log n) ©Павловская Т. А. (СПб НИУ ИТМО) 51
Пример 1: проверка единственности элементов массива n Алгоритм на основе грубой силы попарно сравнивает все элементы, пока не будут найдены два одинаковых либо пока не будут пересмотрены все возможные пары. В наихудшем случае эффективность квадратична. n К решению задачи можно подойти и по-другому - сначала отсортировать массив, а затем сравнивать только последовательные элементы. n Время работы алгоритма - сумма времени сортировки и времени на проверку соседних элементов. n Если воспользоваться хорошим алгоритмом сортировки, весь алгоритм проверки единственности элементов массива также будет иметь эффективность О (n log n) ©Павловская Т. А. (СПб НИУ ИТМО) 51